Unpacking the Concept of Null: A Comprehensive Look at Absence, Its Role, and Implications Across Digital Landscapes
The term "null" permeates various domains within computing, data management, and even philosophical discourse, signifying much more than a mere absence. This exploration seeks to unravel the multifaceted nature of "null," examining its conceptual foundations, practical applications, and the challenges it presents across different technological landscapes.
The Conceptual Foundation of Null
At its core, null signifies an absence of value, a state of being undefined, or an unknown quantity. It is not equivalent to zero, which is a specific numerical value, nor is it an empty string, which is a string containing no characters. Instead, null points to the complete non-existence of a value for a given data item or variable. This fundamental distinction is crucial for understanding its behavior and implications.
Null Across Programming Paradigms
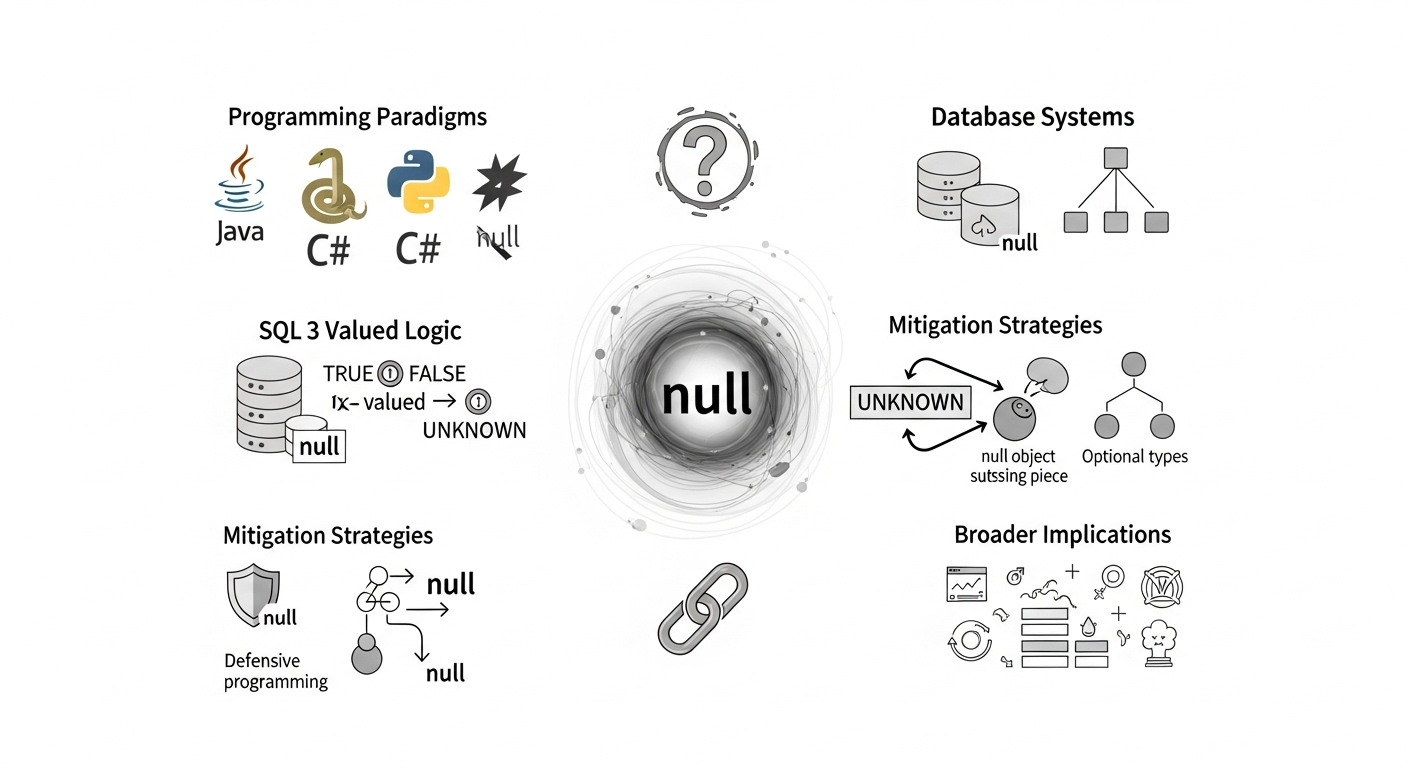
The implementation and interpretation of null can vary significantly across different programming languages, leading to diverse ways of handling this concept. In many object-oriented languages like Java and C#, null is a special literal that represents a reference that does not point to any object. Attempting to access members or methods of a null reference typically results in a runtime error, commonly known as a Null Pointer Exception (NPE) or NullReferenceException.
Other languages adopt similar constructs but use different nomenclature. Python uses None, a singleton object representing the absence of a value. Ruby employs nil, which is an instance of the NilClass. In C and C++, NULL is often a macro that expands to an integer constant 0 or (void*)0, representing a null pointer. These variations, while syntactically distinct, all serve the primary purpose of indicating the lack of a valid referent or value.
The historical perspective on null is also noteworthy. Sir Tony Hoare, a British computer scientist, famously referred to the invention of the null reference in ALGOL W in 1965 as his "billion-dollar mistake." This characterization stems from the enormous debugging costs and system crashes attributed to null pointer errors over decades. The pervasive nature of these errors underscored the need for more robust strategies to manage or mitigate the risks associated with null.
Null in Database Systems: SQL's Unique Approach
Within relational database management systems (RDBMS), particularly those adhering to SQL standards, NULL takes on a slightly different, yet equally significant, meaning. In SQL, NULL indicates that a data value is unknown or missing. It is not the same as an empty string ('') or a zero (0). For instance, a column for a person's middle name might contain NULL if the information is unavailable, as opposed to an empty string which might imply they explicitly don't have a middle name.
The handling of NULL in SQL introduces complexities, primarily through its interaction with comparison operators and logical expressions. SQL's three-valued logic (3VL) incorporates TRUE, FALSE, and UNKNOWN. Any comparison involving NULL (e.g., value = NULL or value != NULL) evaluates to UNKNOWN, not TRUE or FALSE. This behavior often surprises those unfamiliar with SQL's specifics and necessitates the use of special predicates like IS NULL and IS NOT NULL to accurately check for the presence or absence of a value. The implications of this 3VL extend to aggregate functions, where NULL values are typically ignored, and to unique constraints, where the behavior can vary between database systems.
The Role of Null in Data Structures and Algorithms
Beyond variables and database fields, null plays a vital structural role in many data structures. In linked lists, a null pointer typically marks the end of the list, indicating that there are no further nodes. Similarly, in tree structures, null references are used to denote the absence of a child node, signifying the leaf nodes or empty branches. These applications of null are foundational, allowing algorithms to traverse structures and correctly identify their boundaries.
However, these uses also carry the inherent risk of dereferencing a null pointer if not handled with care. Algorithms must explicitly check for null before attempting to access the next element or child, a common source of bugs if neglected. The clarity provided by a definitive end-of-structure marker is balanced by the need for meticulous error handling.
Addressing the Challenges of Null: Mitigation Strategies
Given the challenges and potential for errors associated with null, various strategies have emerged to manage its presence and mitigate its risks. These approaches aim to make code more robust, readable, and less prone to runtime failures.
1. Defensive Programming
One fundamental strategy is defensive programming, where developers explicitly check for null values before operating on them. This often involves if (variable != null) checks or similar constructs to ensure that a reference is valid before being used. While effective, this can lead to verbose code with numerous null checks, sometimes obscuring the primary logic.
2. The Null Object Pattern
The Null Object pattern offers an elegant solution by providing an object that encapsulates the behavior of null. Instead of returning null, a method returns a special "null object" that implements the same interface as the real object but performs no action or provides default, safe behavior. This eliminates the need for explicit null checks, as all objects (real or null) respond to messages in a defined way, reducing the risk of runtime errors and simplifying code.
3. Optional Types and Maybe Monads
Functional programming paradigms and newer language features have introduced concepts like "Optional" types (e.g., Optional<T> in Java, Option<T> in Scala and Rust) or "Maybe monads." These types explicitly represent the possibility of a value's absence. Instead of a variable potentially being null, it's either `Some(value)` (containing a value) or `None` (containing no value). This forces developers to acknowledge and handle both cases at compile time, making null-related errors far less likely at runtime. This approach shifts the responsibility of handling absence from implicit runtime checks to explicit compile-time declarations and pattern matching.
4. Non-nullable Types
Modern type systems are increasingly incorporating non-nullable types, where variables are by default assumed to hold a non-null value. If a developer intends for a variable to possibly be null, they must explicitly declare it as nullable (e.g., using a question mark suffix like string? in C# 8+ or Kotlin). This approach makes the intent clear and allows the compiler to enforce checks, preventing accidental dereferencing of null. This compile-time safety significantly reduces the occurrence of null-related runtime errors.
5. Null Coalescing Operators
Many languages provide syntactic sugar for handling null values, such as the null coalescing operator (?? in C#, Swift, PHP, JavaScript, etc.). This operator provides a concise way to specify a default value if an expression evaluates to null. For example, myVariable ?? defaultValue will use myVariable's value if it's not null; otherwise, it will use defaultValue. This simplifies code that would otherwise require an explicit `if` statement for assignment.
The Broader Implications of Null
Beyond the technical implementation, the concept of null touches upon broader areas. In data modeling, understanding when a field truly needs to allow null versus when an empty string or default value is more appropriate is a critical design decision. Permitting null often implies that the information is simply unknown or not applicable, which can have significant implications for data integrity, query performance, and the complexity of business logic.
In user interface (UI) and user experience (UX) design, the representation of missing data or a null state is also important. How an application conveys that certain information is unavailable or undefined can impact user comprehension and satisfaction. Placeholder text, disabled fields, or specific messaging can help users understand when data is genuinely absent, rather than merely uninitialized or empty.
The philosophical underpinnings of null also warrant consideration. The concept of nothingness, absence, or the void has been debated for millennia. In computing, null serves as a pragmatic representation of this absence, enabling systems to distinguish between something that exists (even if it's an empty container) and something that truly does not exist or is undefined in a given context. The evolution of how we handle null reflects an ongoing effort to bridge this abstract concept with concrete computational reliability.
Furthermore, null plays a role in data serialization formats like JSON and XML. In JSON, null is a distinct data type used to denote the absence of a value. When exchanging data between systems, correctly interpreting and handling these null values is crucial to avoid data corruption or misinterpretation. Standard protocols and specifications often detail how null should be represented and processed to ensure interoperability.
Conclusion
The concept of null, while seemingly simple, represents a profound and pervasive element in the landscape of information technology. From its conceptual role in denoting absence to its varied implementations across programming languages and database systems, null presents both fundamental utility and significant challenges. The ongoing evolution of mitigation strategies, from defensive programming to advanced type systems, underscores the importance of carefully managing null to ensure software reliability and data integrity. A thorough understanding of null is essential for anyone engaged with the architecture, development, or analysis of digital systems, reflecting its enduring impact on how we construct and interpret information.